
*That is half #1 of a series the place anybody can ask questions on Geth and I will try and reply the best voted one every week with a mini writeup. This week’s highest voted query was: May you share how the flat db construction is completely different from the legacy construction?*
State in Ethereum
Earlier than diving into an acceleration construction, let’s recap a bit what Ethereum calls state and the way it’s saved at present at its numerous ranges of abstraction.
Ethereum maintains two various kinds of state: the set of accounts; and a set of storage slots for every contract account. From a purely summary perspective, each of those are easy key/worth mappings. The set of accounts maps addresses to their nonce, stability, and many others. A storage space of a single contract maps arbitrary keys – outlined and utilized by the contract – to arbitrary values.
Sadly, while storing these key-value pairs as flat knowledge can be very environment friendly, verifying their correctness turns into computationally intractable. Each time a modification can be made, we might have to hash all that knowledge from scratch.
As a substitute of hashing all the dataset on a regular basis, we may break up it up into small contiguous chunks and construct a tree on prime! The unique helpful knowledge can be within the leaves, and every inside node can be a hash of every little thing under it. This could permit us to solely recalculate a logarithmic variety of hashes when one thing is modified. This knowledge construction truly has a reputation, it is the well-known Merkle tree.
Sadly, we nonetheless fall a bit quick on the computational complexity. The above Merkle tree format may be very environment friendly at incorporating modifications to present knowledge, however insertions and deletions shift the chunk boundaries and invalidate all the calculated hashes.
As a substitute of blindly chunking up the dataset, we may use the keys themselves to prepare the information right into a tree format primarily based on frequent prefixes! This manner an insertion or deletion would not shift all nodes, reasonably will change simply the logarithmic path from root to leaf. This knowledge construction is known as a Patricia tree.
Mix the 2 concepts – the tree format of a Patricia tree and the hashing algorithm of a Merkle tree – and you find yourself with a Merkle Patricia tree, the precise knowledge construction used to symbolize state in Ethereum. Assured logarithmic complexity for modifications, insertions, deletions and verification! A tiny further is that keys are hashed earlier than insertion to stability the tries.
State storage in Ethereum
The above description explains why Ethereum shops its state in a Merkle Patricia tree. Alas, as quick as the specified operations obtained, each selection is a trade-off. The price of logarithmic updates and logarithmic verification is logarithmic reads and logarithmic storage for each particular person key. It is because each inside trie node must be saved to disk individually.
I would not have an correct quantity for the depth of the account trie for the time being, however a few 12 months in the past we have been saturating the depth of seven. This implies, that each trie operation (e.g. learn stability, write nonce) touches no less than 7-8 inside nodes, thus will do no less than 7-8 persistent database accesses. LevelDB additionally organizes its knowledge right into a most of seven ranges, so there’s an additional multiplier from there. The web result’s {that a} single state entry is predicted to amplify into 25-50 random disk accesses. Multiply this with all of the state reads and writes that each one the transactions in a block contact and also you get to a scary quantity.
[Of course all client implementations try their best to minimize this overhead. Geth uses large memory areas for caching trie nodes; and also uses in-memory pruning to avoid writing to disk nodes that get deleted anyway after a few blocks. That’s for a different blog post however.]
As horrible as these numbers are, these are the prices of working an Ethereum node and having the potential of cryptograhically verifying all state always. However can we do higher?
Not all accesses are created equal
Ethereum depends on cryptographic proofs for its state. There is no such thing as a method across the disk amplifications if we wish to retain {our capability} to confirm all the information. That stated, we can – and do – belief the information we have already verified.
There is no such thing as a level to confirm and re-verify each state merchandise, each time we pull it up from disk. The Merkle Patricia tree is crucial for writes, nevertheless it’s an overhead for reads. We can’t do away with it, and we can’t slim it down; however that does not imply we should essentially use it in every single place.
An Ethereum node accesses state in a number of completely different locations:
- When importing a brand new block, EVM code execution does a more-or-less balanced variety of state reads and writes. A denial-of-service block would possibly nonetheless do considerably extra reads than writes.
- When a node operator retrieves state (e.g. eth_call and household), EVM code execution solely does reads (it might probably write too, however these get discarded on the finish and aren’t persevered).
- When a node is synchronizing, it’s requesting state from distant nodes that have to dig it up and serve it over the community.
Based mostly on the above entry patterns, if we will quick circuit reads to not hit the state trie, a slew of node operations will grow to be considerably quicker. It’d even allow some novel entry patterns (like state iteration) which was prohibitively costly earlier than.
After all, there’s all the time a trade-off. With out eliminating the trie, any new acceleration construction is further overhead. The query is whether or not the extra overhead offers sufficient worth to warrant it?
Again to the roots
We have constructed this magical Merkle Patricia tree to resolve all our issues, and now we wish to get round it for reads. What acceleration construction ought to we use to make reads quick once more? Nicely, if we do not want the trie, we do not want any of the complexity launched. We are able to go all the way in which again to the origins.
As talked about to start with of this submit, the theoretical preferrred knowledge storage for Ethereum’s state is an easy key-value retailer (separate for accounts and every contract). With out the constraints of the Merkle Patricia tree nonetheless, there’s “nothing” stopping us from truly implementing the perfect answer!
Some time again Geth launched its snapshot acceleration construction (not enabled by default). A snapshot is a whole view of the Ethereum state at a given block. Summary implementation sensible, it’s a dump of all accounts and storage slots, represented by a flat key-value retailer.
Every time we want to entry an account or storage slot, we solely pay 1 LevelDB lookup as an alternative of 7-8 as per the trie. Updating the snapshot can be easy in concept, after processing a block we do 1 further LevelDB write per up to date slot.
The snapshot primarily reduces reads from O(log n) to O(1) (instances LevelDB overhead) at the price of growing writes from O(log n) to O(1 + log n) (instances LevelDB overhead) and growing disk storage from O(n log n) to O(n + n log n).
Satan’s within the particulars
Sustaining a usable snapshot of the Ethereum state has its complexity. So long as blocks are coming one after the opposite, all the time constructing on prime of the final, the naive method of merging modifications into the snapshot works. If there is a mini reorg nonetheless (even a single block), we’re in hassle, as a result of there is not any undo. Persistent writes are one-way operation for a flat knowledge illustration. To make issues worse, accessing older state (e.g. 3 blocks outdated for some DApp or 64+ for quick/snap sync) is inconceivable.
To beat this limitation, Geth’s snapshot consists of two entities: a persistent disk layer that may be a full snapshot of an older block (e.g. HEAD-128); and a tree of in-memory diff layers that collect the writes on prime.
Every time a brand new block is processed, we don’t merge the writes instantly into the disk layer, reasonably simply create a brand new in-memory diff layer with the modifications. If sufficient in-memory diff layers are piled on prime, the underside ones begin getting merged collectively and finally pushed to disk. Every time a state merchandise is to be learn, we begin on the topmost diff layer and preserve going backwards till we discover it or attain the disk.
This knowledge illustration may be very highly effective because it solves a variety of points. For the reason that in-memory diff layers are assembled right into a tree, reorgs shallower than 128 blocks can merely decide the diff layer belonging to the mum or dad block and construct ahead from there. DApps and distant syncers needing older state have entry to 128 latest ones. The price does improve by 128 map lookups, however 128 in-memory lookups is orders of magnitude quicker than 8 disk reads amplified 4x-5x by LevelDB.
After all, there are heaps and plenty of gotchas and caveats. With out going into an excessive amount of particulars, a fast itemizing of the finer factors are:
- Self-destructs (and deletions) are particular beasts as they should quick circuit diff layer descent.
- If there’s a reorg deeper than the persistent disk layer, the snapshot must be fully discarded and regenerated. That is very costly.
- On shutdown, the in-memory diff layers must be persevered right into a journal and loaded again up, in any other case the snapshot will grow to be ineffective on restart.
- Use the bottom-most diff layer as an accumulator and solely flush to disk when it exceeds some reminiscence utilization. This enables deduping writes for a similar slots throughout blocks.
- Allocate a learn cache for the disk layer in order that contracts accessing the identical historical slot again and again do not trigger disk hits.
- Use cumulative bloom filters within the in-memory diff layers to shortly detect whether or not there’s an opportunity for an merchandise to be within the diffs, or if we will go to disk instantly.
- The keys aren’t the uncooked knowledge (account deal with, storage key), reasonably the hashes of those, making certain the snapshot has the identical iteration order because the Merkle Patricia tree.
- Producing the persistent disk layer takes considerably extra time than the pruning window for the state tries, so even the generator must dynamically observe the chain.
The nice, the dangerous, the ugly
Geth’s snapshot acceleration construction reduces state learn complexity by about an order of magnitude. This implies read-based DoS will get an order of magnitude more durable to drag off; and eth_call invocations get an order of magnitude quicker (if not CPU sure).
The snapshot additionally permits blazing quick state iteration of the latest blocks. This was truly the primary cause for constructing snapshots, because it permitted the creation of the brand new snap sync algorithm. Describing that’s a wholly new weblog submit, however the newest benchmarks on Rinkeby communicate volumes:
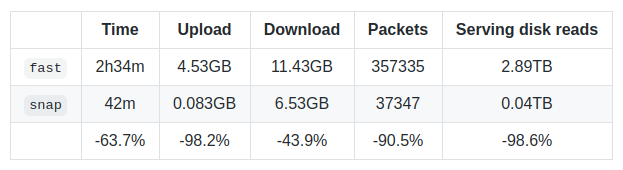
After all, the trade-offs are all the time current. After preliminary sync is full, it takes about 9-10h on mainnet to assemble the preliminary snapshot (it is maintained dwell afterwards) and it takes about 15+GB of extra disk house.
As for the ugly half? Nicely, it took us over 6 months to really feel assured sufficient in regards to the snapshot to ship it, however even now it is behind the –snapshot flag and there is nonetheless tuning and sprucing to be carried out round reminiscence utilization and crash restoration.
All in all, we’re very happy with this enchancment. It was an insane quantity of labor and it was an enormous shot at nighttime implementing every little thing and hoping it can work out. Simply as a enjoyable reality, the primary model of snap sync (leaf sync) was written 2.5 years in the past and was blocked ever since as a result of we lacked the required acceleration to saturate it.
Epilogue
Hope you loved this primary submit of Ask about Geth. It took me about twice as a lot to complete it than I aimed for, however I felt the subject deserves the additional time. See you subsequent week.
[PS: I deliberately didn’t link the asking/voting website into this post as I’m sure it’s a temporary thing and I don’t want to leave broken links for posterity; nor have someone buy the name and host something malicious in the future. You can find it among my Twitter posts.]








{kind=link}